I need some help troubleshooting a problem. We have 3 ePMP 2000 APs on the top of a tower. All three are well grounded and into the same switch that is at the top of the tower as well (and fed by fiber). All three are on 20 Mhz channels with about 15 SMs attached each. None are over loaded.
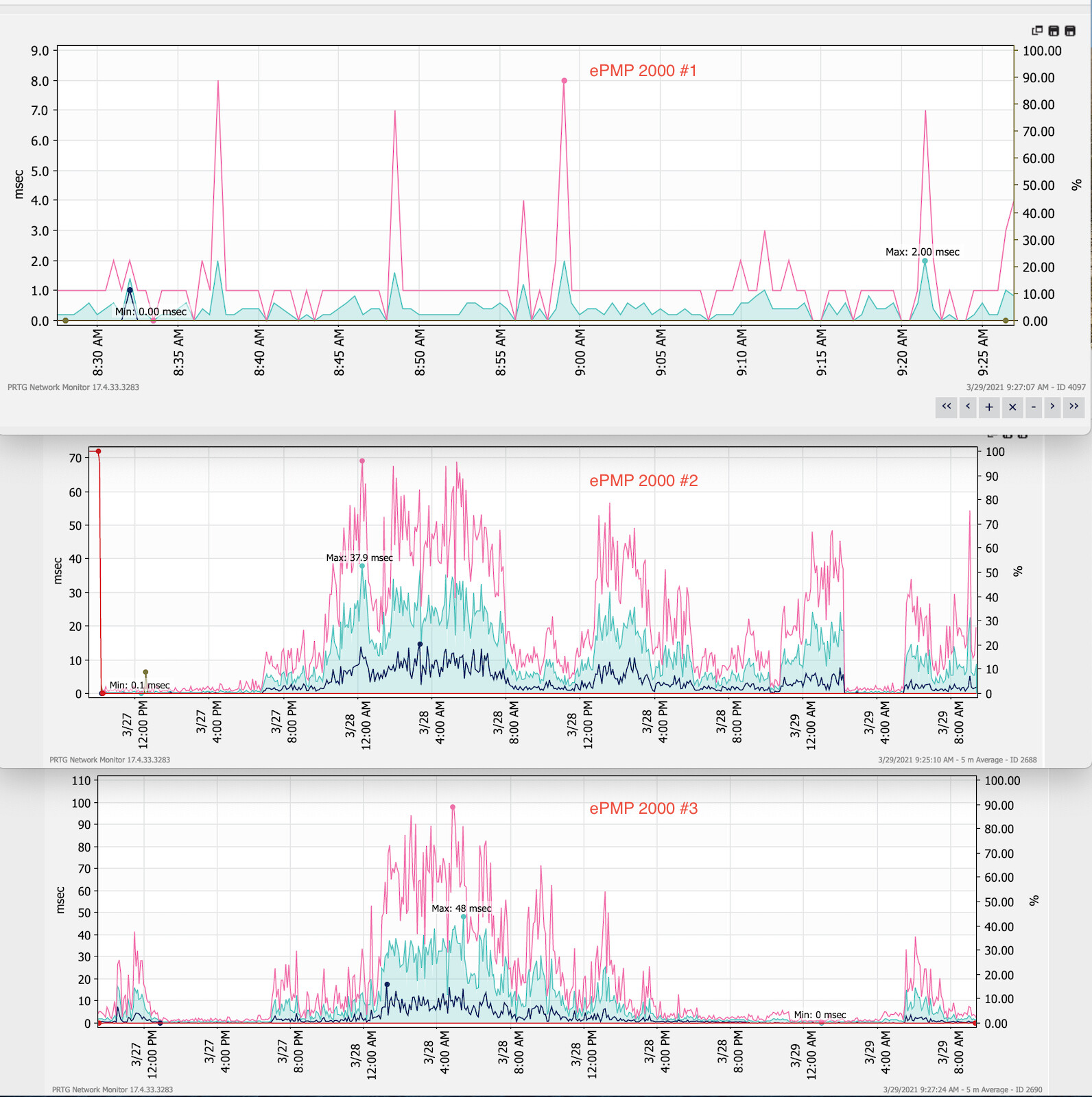
I’ve attached a graph of ping / latency times to each of three APs over a 48 hour period. Radio 1 is perfectly clean and its ping graph also looks just like the graph of the switch powering these radios.
Radio 2 and 3 have nearly identical latency issues - but not exactly the same. We thought we had a bad switch port or bad cable. Cable was replaced on all three radios. We then moved radio 2 off the switch at the top of the tower and powered it via the POE injector and plugged into a switch at the bottom. No improvement at all in latency - still looks terrible and nearly identical to radio 3.
So, I can fairly safely say this is not a cable problem and not a switch problem. Two other radios off that same switch have no latency issues at all.
When I look at graphs of frame utilization, CPU use, re-transmits, etc for those two APs, there is no correlation. CPU does not ever go above 80%, frame utilization rarely goes to 100 and when it does, the graph pattern does not match the latency issue.
My gut tells me I can’t have two bad APs acting almost exactly the same way - but maybe I can?
So, this is pinging the ethernet of the AP, right?
Could it possibly be a routing issue by chance? Have you tried a “traceroute” from the command prompt to see if the data happens to be going ‘the long way around’ somewhere between your graphing computer and these AP’s?
All three APs are in the same subnet - one IP different from the next. Pinging device has only one way to get there and back - it’s a single hop from the PRTG server to the APs.
I like the idea of pinging through the device. We are now graphing that on all three APs to see what we learn there.
Ip space being thame same does not rule out routing issues, neither does one hop distance.
Get out your wireshark, create a span port and listen to those APs. If you have a default route configured but its going to another device first then you could fix this by removing the default route. If those ports are having spanning tree issues then you will see odd behavior just on those ports unless you switch does device based spanning tree configurations, then it will follow the mac address. CDP and LLDP are useful if all devices use these protocols else they cause issues that will make you tear your hair out. Hell even ICMP priorities could be set wrong so these APs just do not prioritize a ping.
Too much to guess on based soley on a ping problem.
You are correct on too much to guess with just a ping problem but a ping problem will often do a decent job of unveiling a problem somewhere. We have CDP and LLDP turned off on all our APs and STP is off on all switches since we are fully routed. We do have priority set to “7” on the management interface and firewalls and QOS are not used and off.
There may not be a “problem” but having 2 of 5 devices on a network segment acting in nearly identical ways with latency caught our eye. We are doing latency checks through the APs now to see if patterns through the AP match the latency pattern of the AP itself. That should tell us if there really is an issue or if the AP is just responding slowly at times to pings.
We do not worry about the latency to the AP unless it is stupidly high, but then again our tower switches would be filling our log servers with lots of complaints then too.
Testing through an AP is almost impossible to use as a comparison to another unless exactly the same number of SMs are connected with exactly the same throughput being used across the SMs. We watch the backhauls, those are more likely where latency issues will be shown.
What do your channel settings and spectrum scans look like? This sounds more like an interference issue. I’d check your guard interval, co location mode settings and other RF related parameters. A long guard interval might help but without knowing what your sector widths are and other things its hard to say if these are bad.
I doubt its an issue with hardware though - seems RF related.
We are using 20 Mhz channels and the spectrum is dead clean. We have an FCC STA that these APs are on (2 of them). A scan reveals we are the only ones on those channels. Guard intervals is short and these three APs happen to be on flexible ratio.
What channels are you using specifically? Is it three 120 sectors? Help me visualize how you have this set up for all 3 radios.
I would recommend trying a set ratio 75/25 with that few subs you shouldn’t need to have it set to flexible this just adds variables to the equation. You can try a long guard interval but if the air is clean you shouldn’t* have to. What are your synchronization settings for the radios? Disable co-location mode unless there are legacy radios nearby. Is your software up to date?
Channels are 5855 and 5880 plus another at 5200 which is not quite as clean. They are in 60 degree horns and not over lapping. We don’t use synchronization on these since we are not doing re-use and it dramatically slows down the upload speeds for customers. We don’t use the co-location setting since sync is off. Software is 4.6-RC35STA in AP and stations. That is the latest STA firmware we have access to.
So I had this problem bite me in the butt with my first Cambium system that I installed but it was a PMP450 ring NOT on my epmp system. It almost drove me crazy. I would start loosing pings, alarms going off all night I would power the AP off and on it would fix the issue then happen again no pattern of reason behind it. Finally I for the sake of trying everything else. Hard set the speed in my switch and the AP to the same setting and presto never got another alarm or dropped packets and latency issues ever again. I thought Auto negotiate would be a great idea but It was my issue all along. It took me replacing cables up down the tower, a new CMM model, Power supplies, surge protection, and bringing AP down and testing in the tower building, 6 months of less sleep then having a new born before I figured that one out. LOL.
sync isnt just for reuse! its to ensure you are not transmitting when another AP is receiving. The guard interval is to give the receiver a change to stabilize before the SMs transmit. Since the radios use the same physical antenna to transmit as they do receive, a little time has to be wasted to bleed the excess energy off the antennas. This is even more important if you have SMs more than a couple miles away as the air delay of the signal also takes time to arrive. Unless your really close, use long. If you have more than one radio within 20 miles of each other use sync so that the APs tx at the same time and you dont shout in to another APs antenna.
As HS-HS has stated there is a possibility that your switch/cable/ap combo isnt working correctly. But I am leaning on an RF side problem, including RF injection on the ethernet cable.
{kind=link}