I just did my first upgrades and i’m monitoring it, so far so good, will hopefully see great results over the next 24 hours before continuing further.
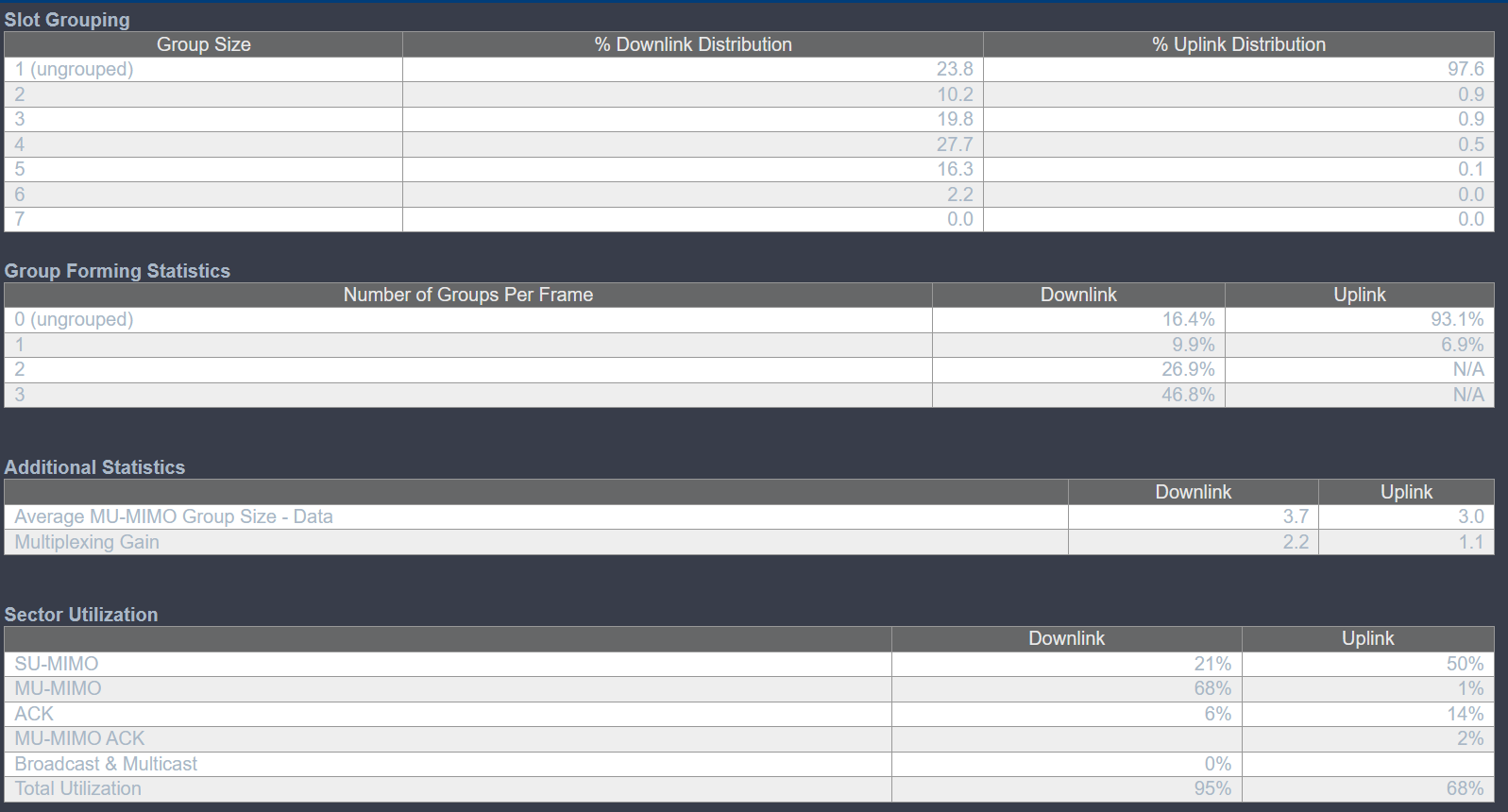
One thing i noticed after the upgrade is that the average group size that was 5 before upgrade has been hovering around 3 for the last hour, but i do see that there’s a decent bit of 2 and 3 groups per frame if i check the stats on the AP.
Does the new feature preference smaller groups and more of them over say a larger grouping? say a group of 2,2,3+sumimo instead of 1 group of 5 and su-mimo? Just trying to understand what i’m seeing/monitoring, as the old docs had us monitoring, average group size for spatial distribution efficiency, and mux-gain for how that traffic is utilized.
We were just trying to figure out how to gauge congestion before this change, any tips on how we can quantify what “congestion” looks like in this new MGPF world?
We’re also monitoring our first AP’s having super low uplink grouping, any tips for that and how to quantify congestion would be great
Yes, as Eric mentions, the release notes have a good writeup on this MGPF feature. The existing group size stats do give a good rough indication of grouping efficiency. But the problem this MGPF feature addresses highlights how this average group size metric is an imperfect metric.
It basically counts and reports frame sizes at the start of frames. Besides a Link Test, it is very common for individual members of a MUMIMO group to no longer have data to send in the latter slots of a frame. Throughput can be improved with our R22.0 code by changing the group members once or twice in the middle of the frame, even if such groups might start off with fewer members. The MUX gain is a better indication of total slot usage in the frame. However, when developing the MGPF feature and the R22.1 scheduling improvement feature being worked on now, we noticed a correction that needed to be made in the MUX gain calculation.
While we now have this calculation correct in 22.0 and later code, you may see a slightly lower downlink MUX gain reported in R22.0 vs prior builds, for similar throughput numbers. So your total sector throughput seen before and after the upgrade to 22.0 is really your best measure of improvement seen with this 22.0 feature.
Regarding how to gauge congestion, that has not really changed with this 22.0 MGPF frame. You continue to use frame utilization percentages to gauge how congested your time space is. Then beyond that, your spatial utilization can continue to be measured, for starters, by looking at MUX Gain. . This slightly lower downlink MUX gain due to the calculation correction would be seen more at large bandwidth configurations like 30 MHz and 40 MHz, and is expected to ~6% or less of a correction. A more detailed analysis then of the spatial utilization statistics can give you an idea as to whether or not you are spatially maxed out or have additional spatial capacity
That’s about what i thought, i think the main reason i ask is that we had our test AP that was basically always at a grouping of 4-5 and since the upgrade seems to have settled mostly on avg 3 but as above, it also has 3 groups happening frequently. I think what confuses me a bit is if previously most traffic (average) was 5 group, shouldn’t that still mean we’d be getting a lot of 5 grouping that tapers off in the frame time to smaller different groups or am i visualizing the frame wrong.
For gauging congestion, our issue tends to be 100% frame utilization tends to mean nothing, because we have 450m’s at 100% frame utilization, but the throughput easily goes up, because other users in different spatial areas pull traffic, so technically theirs more space even at 100% frame usage, just not in the spatial areas that are congested at that time of 100% usage… So it’s really hard to sit back and say “hey these 20 panels are actually starting to reach X statistic that means we need to add additional overlay sectors to take the load”, with 450i it was easy, get to 80% start planning to add an overlay or additional site covering the area… with 450m it’s hard to gauge when MU-MIMO isn’t going to be enough to handle the load sufficiently.
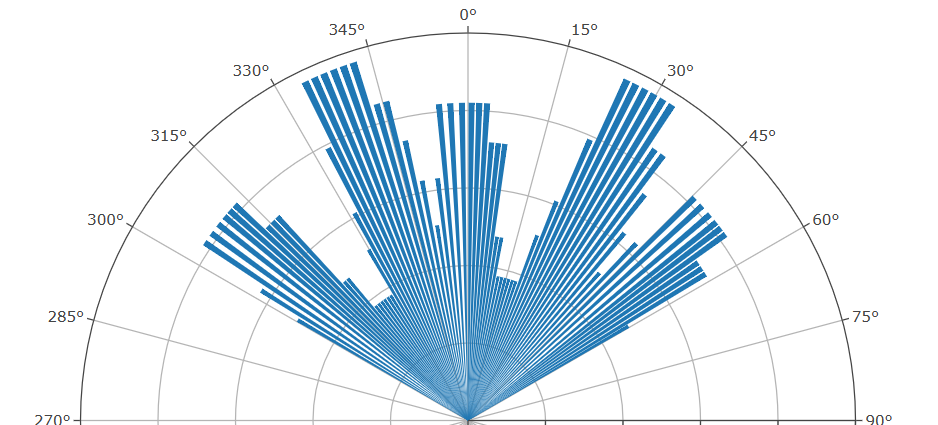
I’m trying to work on my own backend analysis for helping to visualize the physical spatial saturation in relation to the panels azimuth to help us figure out where we actually have over-saturation of clientele and where we have holes for more clients in relation to the panel, not easy to do on the current heat map, but with some bending into a wind rose chart it visualizes it a bit better…
For your question on the Slot Grouping statistics table, if hypothetically you were showing 100% groups of 5 prior to an upgrade to 22.0, I would typically expect at least 33% of your downlink distribution would show groups of 5 after the upgrade, with possibly smaller group sizes for the remaining 66% of the distribution. I suppose it’s possible to see less than 33% groups of 5 after an upgrade in this hypothetical example if the new code is more efficiently emptying the queues in your deployment. A developer in our team is working on a small document that will explain this better than I can. Look for a posting here or in the knowledge base soon on that.
And yes, I agree with everything you stated regarding how to determine when you are congested or not. It is more complicated with a 450m than with a 450i where you only had to look at the time slot congestion, not your spatial utilization. I like the chart you put together. Just 1 important note, in case you were not aware of it, a single pattern of spatial frequencies does not cover the entire Azimuth your antenna pattern covers, it repeats. How much Azimuth 1 pattern covers depends on the exact center frequency you are operating on. It could be, for example, 50 degrees of Azimuth, or maybe 54 degrees of Azimuth for a 5GHz sector. Or maybe 37 degrees for a 3GHz sector. You can check this on the Statistics Sounding. You can see the sector this statistics screenshot below is taken from has a single cycle covering about 54.2 degrees of Azimuth with a 5520 Mhz center frequency.
So, in your chart, it looks like at first glance you have possible opportunity at 15 degrees of Azimuth. But you would need to also check for congestion 1 cycle away. If your center frequency happened to be 5520 MHz, that would be 320.8 degrees.
In the old documentation it showed that for instance a group consumes say 70% of the frame but certain SMs inside the group may not use the entire groups duration. So at least on uplink the SMs use that time to rebroadcast their data i guess for error correction,
With the new MGPF i’m wondering, i know that this allows for a group, to send its data, and then another group to send its data once that first group is done and continue until no groups are left right?
My question is what about the situation where say a group of 3 has 60% of the frame reserved, but 2 of them finish after 30% of the frame, does the new MGPF wait for the 60% is done transmitting to send another group, or does the scheduler say "hey, i’ve got the entire rest of the spatial area free now, and these 2 SMs have finished, so i can start a new group in all the spatial areas except the one that’s still transmitting from the first group?
I know the pictures of uplink but thats whats in the document But just wondering in downlink at least, where does the scheduler start the next grouping? does it wait for the entire group to finish it’s downlink, or does it try to weave in the groups tighter as the individual downlinks finish to possibly group SMs in the spatial areas that aren’t still transmitting?
Chris, I’m impressed you are this interested in the details of this improvement. I believe some of what you are asking is a bit too proprietary to post here, but I’ll reach out via private chat to you.
Ahh ok, ya i worried you’d say that, just sorta wondered as trying to envision what else is possible inside of the SDA side of the frame arrangement with the new grouping layout, as it’s great to see some solid throughput jumps coming to the 450m.